参数砍到对手四分之一,分数却反超登顶——Qwen3 的“2507”小升级只用 235B 体量就把 1T 的 Kimi K2 拉下马,AIME25 从 24.7% 飙到 70.3%,256K 长文本也一口气吃透。开源大模型的王座还没坐热,就已变成中国队的内部循环赛:DeepSeek→Kimi→Qwen,下一棒随时到站。可灵ai国际版

开源大模型正在进入中国时间。可灵ai国际版
Kimi K2风头正盛,然而不到一周,Qwen3就迎来最新升级,235B总参数量仅占Kimi K2 1T规模的四分之一。ai智能体十大龙头
基准测试性能上却超越了Kimi K2。千问是个什么软件
Qwen官方还宣布不再使用混合思维模式,而是分别训练Instruct和Thinking模型。a1官方免费下载
所以,此次发布的新模型仅支持非思考模式,现在网页版已经可以上线使用了,但通义APP还未见更新。a1官方免费下载

Qwen官方还透露:这次只是一个小更新!大招很快就来了!可灵ai国际版

但总归就是,再见Qwen3-235B-A22B,你好Qwen3-235B-A22B-2507了。kimi手机版
[fancyad id=”45″]商汤科技
By the way,这个名字怎么取得越来越复杂了。kimi手机版

先来看看这次的“小更新”都有哪些~kimi手机版
增强了对256K长上下文的理解能力ai无限制词,免费
新模型是一款因果语言模型,采用MoE架构,总参数量达235B,其中非嵌入参数为234B,推理时激活参数为22B。人工智能ia
在官方介绍中显示,模型共包含94层,采用分组查询注意力(GQA)机制,配备64个查询头和4个键值头,并设置128个专家,每次推理时激活8个专家。人工智能ia
该模型原生支持262144的上下文长度。百度ai虚拟聊天
这次改进主要有以下几个方面:al工具
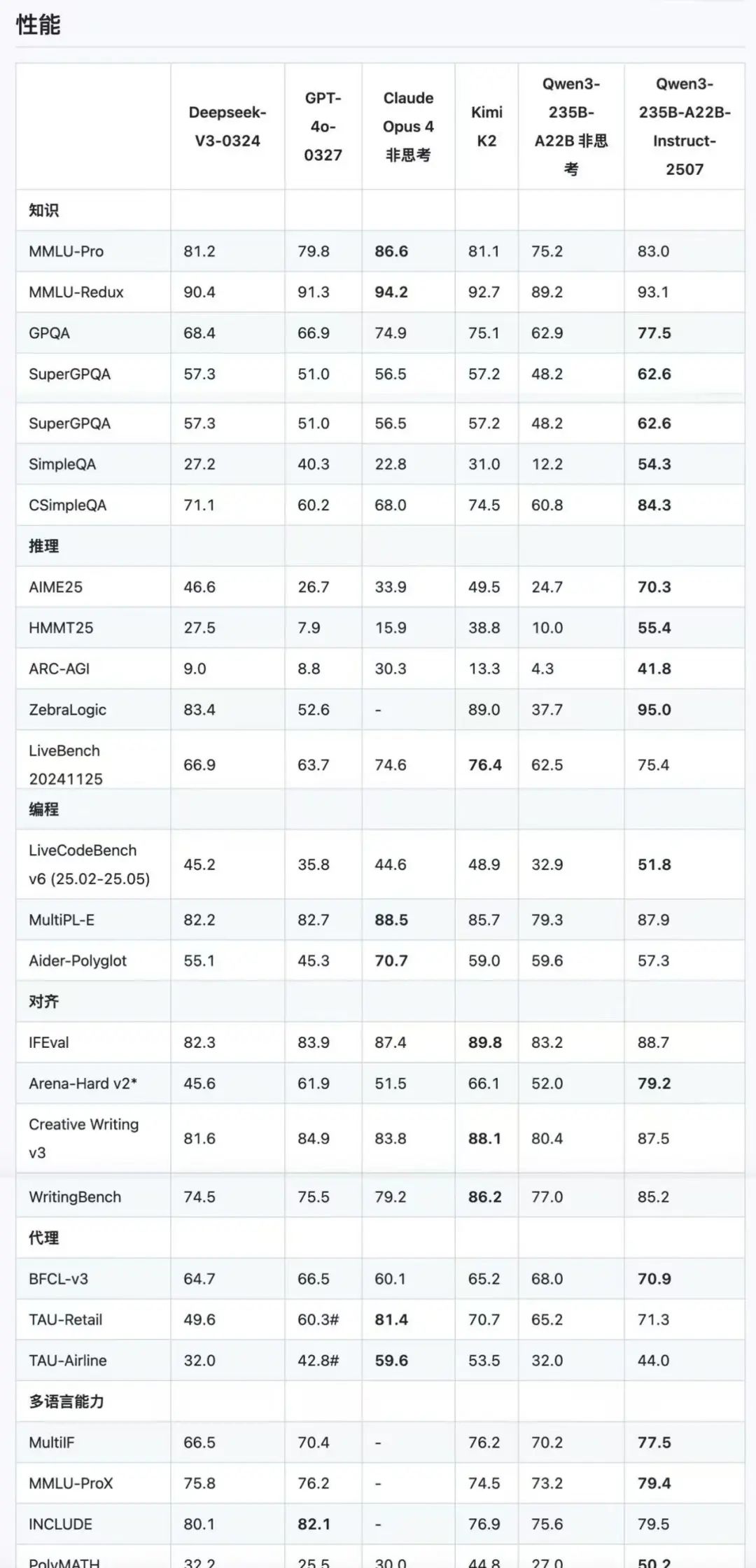
- 显著提升了通用能力,包括指令遵循、逻辑推理、文本理解、数学、科学、编码和工具使用。
- 大幅增加了多语言长尾知识的覆盖范围。
- 更好地符合用户在主观和开放式任务中的偏好,能够提供更有帮助的响应和更高质量的文本生成。
- 增强了对256K长上下文的理解能力。
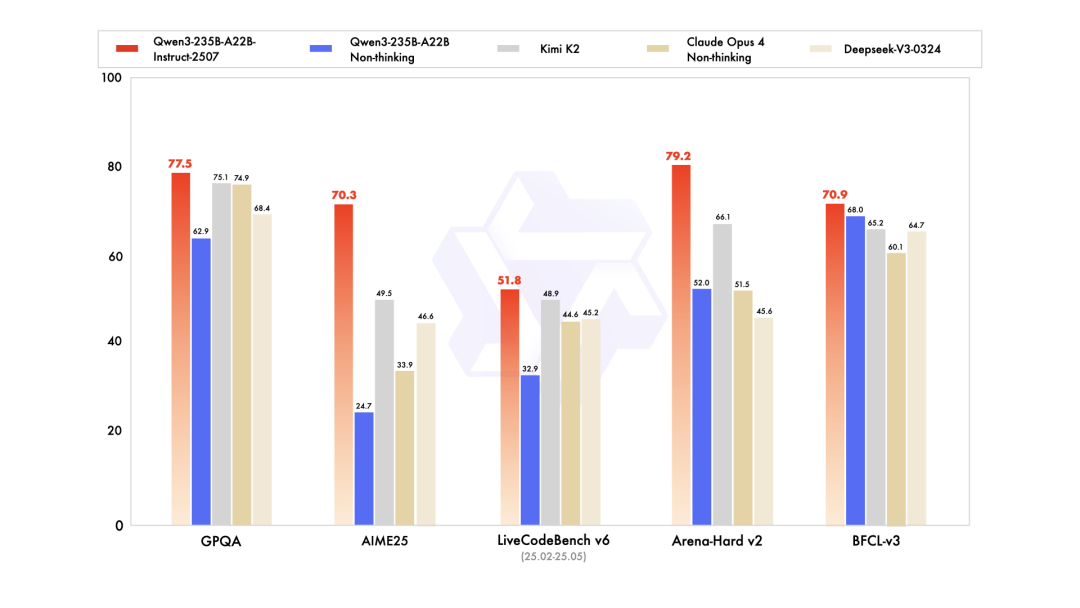
在官方发布的基准测试中可以看到,相较于上一版本,新模型在AIME25上准确率从24.7%上升到70.3%,表现出良好的数学推理能力。ai的可怕之处
而且对比Kimi K2、DeepSeek-V3,Qwen3新模型的能力也都略胜一筹。al解说大师下载
为了提高使用体验,官方还推荐了最佳设置:智能体和ai的区别

Qwen3新版本深夜发布就立刻收获了一众好评:Qwen在中等规模的语言模型中已经领先。viggle ai
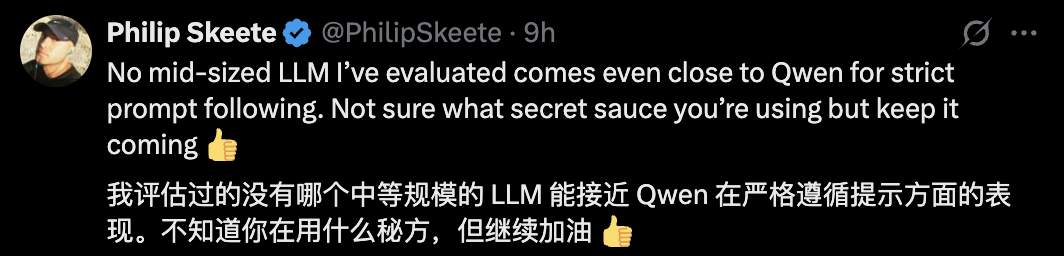
也有网友感慨Qwen在开启新的架构范式:可灵ai国际版

One More Thingagent智能体
有趣的是,就在Qwen3新模型发布的前两天,NVIDIA也宣称发布了新的SOTA开源模型OpenReasoning-Nemotron。千问是个什么软件
该模型提供四个规模:1.5B、7B、14B和32B,并且可以实现100%本地运行。kimi手机版
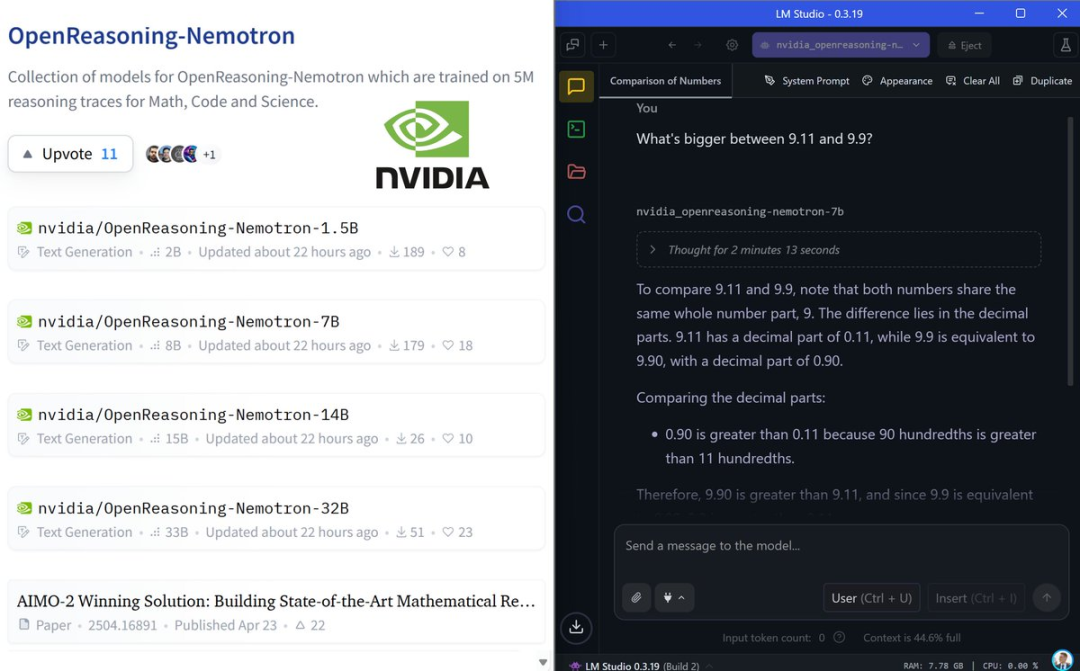
但实际上,这只是基于Qwen-2.5在Deepseek R1数据上微调的模型。al工具

而现在Qwen3已经更新,大招已经被预告。ai开源什么意思
随着Llama转向闭源的消息传出,OpenAI迟迟不见Open,开源基础大模型的竞争,现在正在进入中国时间。可灵ai国际版
DeepSeek丢了王座,Kimi K2补上,Kimi K2坐稳没几天,Qwen的挑战就来了。豆包打开
体验链接:https://chat.qwen.ai/ai开源什么意思
参考链接:ai智能找客户
[1]https://x.com/Alibaba_Qwen/status/1947344511988076547即梦官网网页版
[2]https://x.com/giffmana/status/1947362393983529005龙虾ai下载
闻乐 发自 凹非寺量子位 | 公众号 QbitAIai开源什么意思